
Hi friends,
In this post, we will discuss the DBSCAN (Density-based Spatial Clustering of Applications with Noise) clustering algorithm. DBSCAN is one of the most common clustering algorithms.
Parameters:
The algorithm takes two important parameters:
- Epsilon - also called the neighborhood value is the distance-measure based on which the similarity between the points is defined. Two points are said to belong to the same cluster if they are at most epsilon distance apart
- minpts - the minimum number of points required to form a cluster
Important points:
- In DBSCAN, a single object is represented as a numerical point in some space.
- A neighborhood of a point includes the set of all points that are at most epsilon distance apart from it
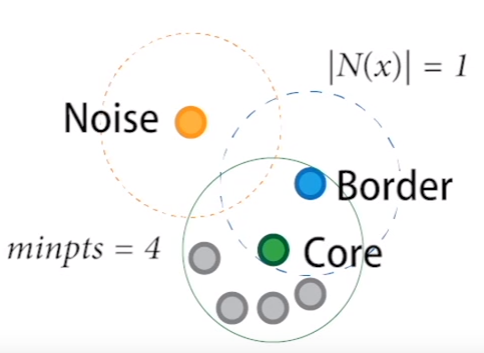
- A point in a DBSCAN can of three types:
- core point - which has at least minpts points in its neighborhood
- border point - one which has a core point in its neighborhood
- noise point - one which is neither a core nor a border point and is considered an outlier in the dataset
Algorithm:
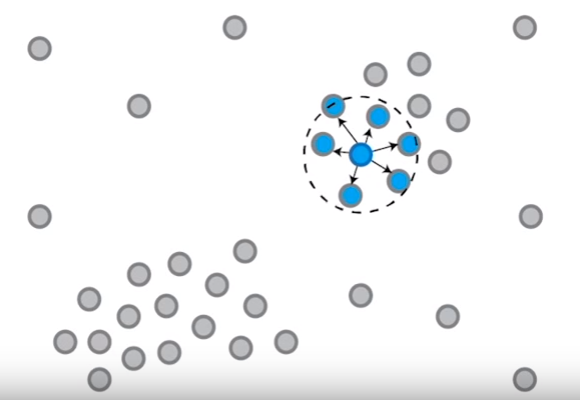
- The DBSCAN starts with a random point and performs a DFS (depth first search) from that point to identify it neighbors
- It recursively applies the DFS for each of the identified neighborhood points until there can be no more points that can be added to the set. This resulting tree structure represents a cluster in the DBSCAN algorithm.
- The DBSCAN repeats with steps 1 and 2 until all the points in the dataset are explored


Advantages of DBSCAN:
- It can discover any number of clusters
- Clusters of varying shapes and sizes can be obtained using the DBSCAN algorithm
- It can detect and ignore outliers
Disadvantages of DBSCAN:
- The epsilon value is too sensitive
- too small a value can result in elimination of spare clusters as outliers
- too large a value would merge dense clusters together giving incorrect clusters
Refer this link to view the video tutorial of the same.

0 comments:
Post a Comment