
Hi friends,



Welcome to another post under Data Science & Machine Learning. In the previous post, we discussed how to read and write data from and to various sources such as csv files, excel files, etc. using Pandas DataFrames.
This post however will be different from the other ones in a way that we will not be learning anything new in this post but will be reviewing the concepts we have learnt till now using the SF Salaries Dataset available at the Kaggle website. Download the dataset from this Kaggle link. You will be required to login there in order to download the dataset. Once downloaded, copy and paste the csv file to your Jupyter Notebook.
Note: All the commands discussed below are run in the Jupyter Notebook environment. See this post on Jupyter Notebook to know about it in detail.
First, import the downloaded Salaries dataset using the read_csv method supported by the Pandas library:
Let's first see a few entries of the SF Salaries Dataset using the head method:
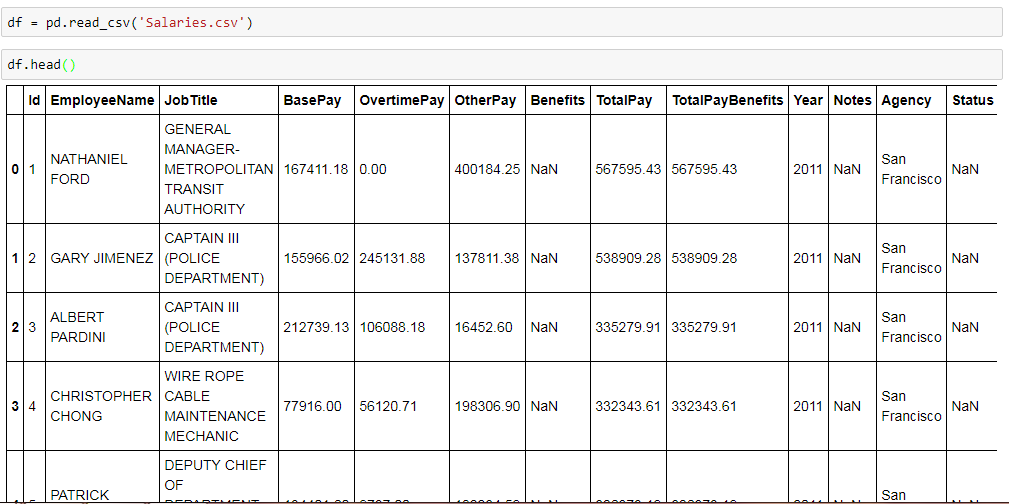
We can see that the dataset has the following columns:
- Id
- EmployeeName
- JobTitle
- BasePay
- OvertimePay
- OtherPay
- Benefits
- TotalPay
- TotalPayBenefits
- Year
- Notes
- Agency
- Status
We can find the total number of entries in the SF dataset using the info method:
Now, let's answer some relevant questions using the concepts we have gathered till now:
- Unique Job Titles in the dataset:
- Top 10 most common Job Titles:
- Average BasePay of the dataset:
- Maximum amount of OvertimePay of the dataset:
- JobTitle of ALBERT PARDINI:
- TotalPayBenefits of ALBERT PARDINI:
- Individual with highest TotalPayBenefits in the dataset:
- Average TotalPay year-wise:
- Number of individuals with Chief in their Job Title: This involves lambda expression and might appear tricky at first sight but I suggest to break it down into sub steps for clear understanding.







We can get the above result using the advance argmax method as well:



It is always advisable to explore various datasets from Kaggle or other websites since Data Science is not about just reading the theory but applying those concepts to datasets and gain insights to achieve a desirable output. From the next posts on ward, we'll start learning about another very important aspect of Data Science i.e. Data Visualizing.

Nice Blog.Thanks for sharing.
ReplyDeleteFor Online MBA check below.
Innomatics Research Labs is collaborated with JAIN (Deemed-to-be University) and offering the Online MBA in Artificial Intelligence & Business Intelligence Program. It is a sublime program of getting an MBA degree from one of the best renowned university – JAIN University and an IBM certification program in Data Science, Artificial Intelligence, and Business Intelligence from Innomatics Research Labs in collaboration with Royal Society London.
Online MBA in Data Science
Online MBA in Business Analytics
Online MBA in Business Intelligence