Hi friends,
Welcome to the post on Pandas DataFrames under Data Science & Machine Learning. In the previous post, we discussed the Series data structure supported by Pandas. In this and a couple of next posts, we'll learn about the Pandas' DataFrames.
Note: All the commands discussed below are run in the Jupyter Notebook environment. See this post on Jupyter Notebook to know about it in detail.
Note: All the commands discussed below are run in the Jupyter Notebook environment. See this post on Jupyter Notebook to know about it in detail.
Pandas DataFrames
Pandas DataFrame is a 2-dimensional labeled data structure with columns of potentially different types. It is like the Microsoft Excel of Python which provides tons for features for efficient data analysis.
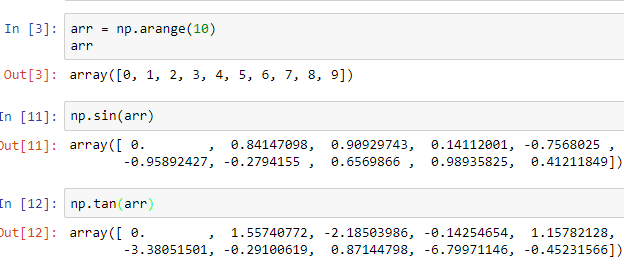
Before beginning to start working with the Pandas DataFrames, remember to import the NumPy and the Pandas libraries.
We will create our first DataFrame with random values so we import the randn library provided by NumPy library as well to generate random numbers.

Now, let's begin using the Pandas DataFrames for better understanding. The three important parameters that Pandas DataFrames takes are:
- Data - The data values of the DataFrame
- Index - The row labels for the DataFrame
- Columns - The column labels for the DataFrame

So, let's first declare the index and the columns as two lists and then fill the DataFrame with the random values. In the below example, I have created a DataFrame of dimensions 4x5.

We can find the size of the DataFrame using the shape attribute of the DataFrame:

Note: Each of the columns in the DataFrame is a series in itself. We can verify that by just printing the type of one of the columns:

Note: Each of the columns in the DataFrame is a series in itself. We can verify that by just printing the type of one of the columns:

You can also use the object-oriented notion(using . operator) to select a column:
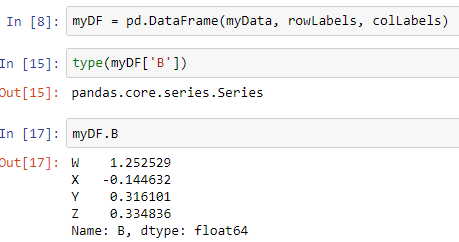
However, the dot(.) notation is usually avoided since it is mostly used for calling various methods on the DataFrame object.
We can also access multiple columns of the DataFrame by passing the list of columns inside the [] brackets:

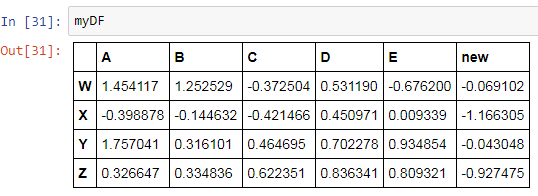
We can even add a column to the DataFrame using the following step:

We can also drop a column from the DataFrame:
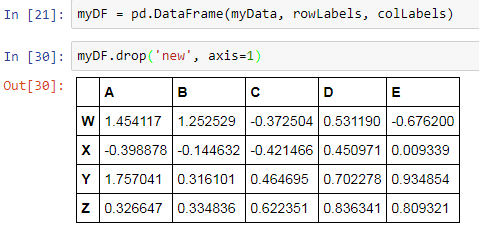
The additional parameter axis is whether we want to delete the row or the column. The value 0 for axis represents the rows and the value 1 represents the columns. Thus, as we want to delete the column new, so we set the value of axis as 1.
However, it does not drop the column permanently from the DataFrame which you can verify by printing the DataFrame again which shows the dropped column as it is:
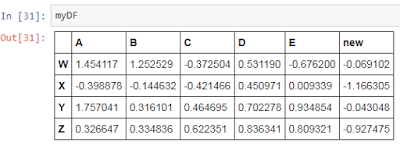
However, it does not drop the column permanently from the DataFrame which you can verify by printing the DataFrame again which shows the dropped column as it is:
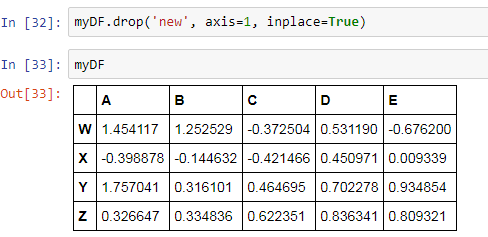
This is done by Python to avoid any accidental deletion of data from the DataFrame. Thus, to delete the column permanently, we need to set the inplace parameter of the drop method to be True:

Notice above that the new column has been permanently deleted from the DataFrame.
We now see how to access the rows of a DataFrame. Accessing a row of a DataFrame is not as trivial as selecting the columns. Pandas support the method loc() to access the rows by its labels or method iloc() to access the row by its index. Here is the usage of each of them:

We can also select part of the DataFrame using the NumPy notation of accessing the 2-D arrays.

We end this post here on basics of Pandas DataFrames. From the next post, we dive into more detail things we can do with Pandas DataFrames.
Notice above that the new column has been permanently deleted from the DataFrame.
We now see how to access the rows of a DataFrame. Accessing a row of a DataFrame is not as trivial as selecting the columns. Pandas support the method loc() to access the rows by its labels or method iloc() to access the row by its index. Here is the usage of each of them:

We can also select part of the DataFrame using the NumPy notation of accessing the 2-D arrays.

We end this post here on basics of Pandas DataFrames. From the next post, we dive into more detail things we can do with Pandas DataFrames.